
概要
やりたいこと
前回 Glue Job で Parquet 形式に変換することができた。
しかし2つの問題がでてきた。
- Glue Job の対象が指定したバケット内のログ全てのため、過去に変換したログも対象としてしまい、重複したログが出てくる
- Glue Job を定期実行できていない
1の問題
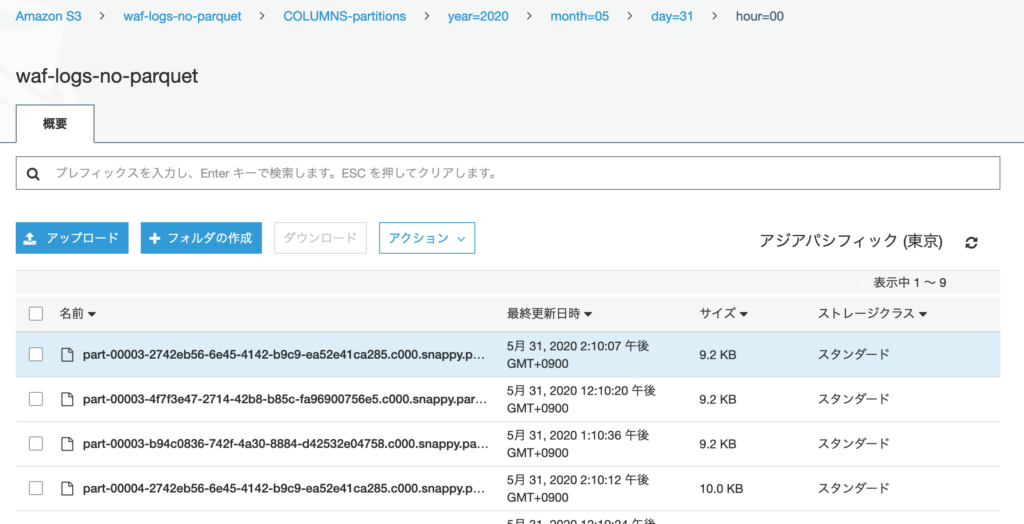
こちら変換前のログ。 year=2020/month=05/day=31/hour=00 パーティション内にはログファイルが3つ。
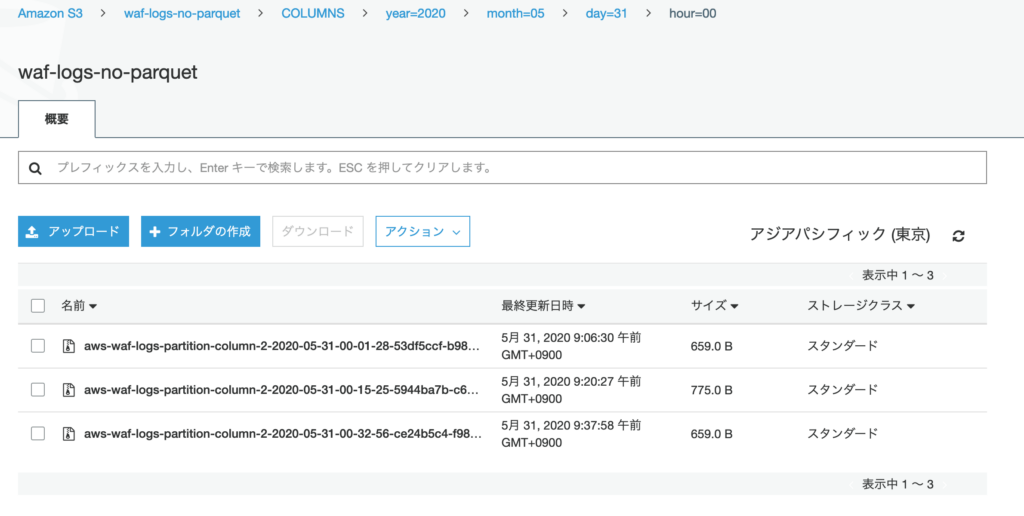
こちらが変換後のログ。year=2020/month=05/day=31/hour=00 パーティション内にログファイルが9つ。
Glue Job を3回実行したため、重複したログが 3 つ出てきしまう。
2の問題
Glue Job を手動で実行するのは辛い。
プッシュダウン述語を使用した事前フィルタ処理
1の問題を解決する。
特定のパーティションのデータのみを対象とできればよい。
このパーティションのフィルタリングを行うには push_down_predicate (プッシュダウン述語)を利用する。
from_catalog 内で指定し、読むコムパーティションを制限する。
例えば、以下はyear=2020/month=05/day=31/hour=04
partition_predicate = "year='2020' and month='05' and day='31' and hour='04'"
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "glue-datacatalog",
table_name = "columns",
push_down_predicate = partition_predicate,
transformation_ctx = "datasource0")
ただし、上記のようにパーティションをハードコーティングしてしまうと、そのパーティションしか読み込まない Glue Job になってしまう。
AWS WAF Log は時刻までパーティションで区切られるため、毎時で実行する。 17時に実行する場合、直前の hour=16 のパーティションを作成してほしい。
from datetime import datetime, timedelta, timezone
now = datetime.now(timezone.utc)
target = now - timedelta(hours=1)
year = str(target.year)
month = str(target.month) if target.month > 10 else '0' + str(target.month) if target.day > 10 else '0' + str(target.day)
day = str(target.day)
hour = str(target.hour) if target.hour > 10 else '0' + str(target.hour)
partition_predicate = "year='" + year + "' and month='" + month + "' and day='" + day + "' and hour='" + hour + "'"
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "glue-datacatalog",
table_name = "columns",
push_down_predicate = partition_predicate,
transformation_ctx = "datasource0")
このやり方だと最短でも 1 時間の差がでる。リアルタイム性がない。。
ログファイルが配置されたら Glue Job を動かすトリガーを Lambda で作ったほうがいいのか?
AWS Glue Workflows
2の問題を解決する。
Glue Job と Glue Crawler の相互に依存するフローを管理してくれる。
今回は以下のフローを管理したい。
- Crawler でS3上のファイルを読み込み、データカタログを作成
- Job で Parquet 形式に変更する
- Crawler で変換後のデータを読み込み、データカタログを作成
Glue Trigger でも Glue Job を定期実行できる。
ただし、Glue Job の処理(2) の前には Glue Crawler の処理(1)が必須、などの ETL 処理全体の依存関係を管理できない。
AWS コンソールから操作
Glue Job 修正
push_down_predicate を追加。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from datetime import datetime, timedelta, timezone
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
now = datetime.now(timezone.utc)
target = now - timedelta(hours=1)
year = str(target.year)
month = str(target.month) if target.month > 10 else '0' + str(target.month)
day = str(target.day)
hour = str(target.hour) if target.hour > 10 else '0' + str(target.hour)
partition_predicate = "year='" + year + "' and month='" + month + "' and day='" + day + "' and hour='" + hour + "'"
#partition_predicate="year='2020' and month='05' and day='31' and hour='05'"
## @type: DataSource
## @args: [database = "glue-datacatalog", table_name = "columns", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "glue-datacatalog",
table_name = "columns",
push_down_predicate = partition_predicate,
transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("timestamp", "long", "timestamp", "long"), ("formatversion", "int", "formatversion", "int"), ("webaclid", "string", "webaclid", "string"), ("terminatingruleid", "string", "terminatingruleid", "string"), ("terminatingruletype", "string", "terminatingruletype", "string"), ("action", "string", "action", "string"), ("terminatingrulematchdetails", "array", "terminatingrulematchdetails", "array"), ("httpsourcename", "string", "httpsourcename", "string"), ("httpsourceid", "string", "httpsourceid", "string"), ("rulegrouplist", "array", "rulegrouplist", "array"), ("ratebasedrulelist", "array", "ratebasedrulelist", "array"), ("nonterminatingmatchingrules", "array", "nonterminatingmatchingrules", "array"), ("httprequest", "struct", "httprequest", "struct"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("timestamp", "long", "timestamp", "long"), ("formatversion", "int", "formatversion", "int"), ("webaclid", "string", "webaclid", "string"), ("terminatingruleid", "string", "terminatingruleid", "string"), ("terminatingruletype", "string", "terminatingruletype", "string"), ("action", "string", "action", "string"), ("terminatingrulematchdetails", "array", "terminatingrulematchdetails", "array"), ("httpsourcename", "string", "httpsourcename", "string"), ("httpsourceid", "string", "httpsourceid", "string"), ("rulegrouplist", "array", "rulegrouplist", "array"), ("ratebasedrulelist", "array", "ratebasedrulelist", "array"), ("nonterminatingmatchingrules", "array", "nonterminatingmatchingrules", "array"), ("httprequest", "struct", "httprequest", "struct"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://waf-logs-no-parquet/COLUMNS-partitions/"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(
frame = dropnullfields3,
connection_type = "s3",
connection_options = {"path": "s3://waf-logs-no-parquet/COLUMNS-partitions/", "partitionKeys": ["year", "month", "day", "hour"]},
format = "parquet",
transformation_ctx = "datasink4")
job.commit()
Glue Workflows 作成
公式の ワークフローの作成と実行 を読んでもいいけど、GUIからクリックして作っていくタイプなので、実際に触ったほうが早い。
ワークフロー名を以下として作成。
- waf-to-parquet
作成したワークフローを選択し、下部に表示されるグラフにトリガーとジョブとクローラを配置していく。
最初に大元となるトリガー1を作成し、その後ろにクローラとトリガーとジョブを連結していく。
最終的には以下のようなトリガーとジョブトークローラが連結した図ができあがる。
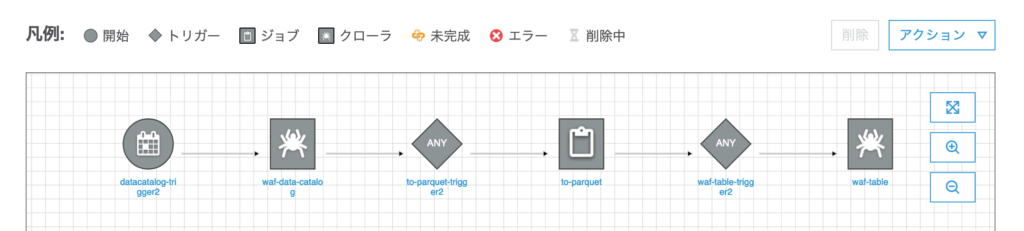
- トリガー1 : クローラ1をスケジュール(毎時)で起動
- クローラ1 : S3上のログからデータカタログを作成
- トリガー2 : クローラ1が完了したらジョブ1を起動
- ジョブ1 : クローラ1で作ったデータカタログより parquet 形式のログをS3に保存
- トリガー3 : ジョブ1が完了したらクローラ2を起動
- クローラ2 : ジョブ1が作成したS3上のログからデータカタログを作成
ワークフローの実行中に、現在どこの処理を行っているかをグラフ上に表示してくれる。
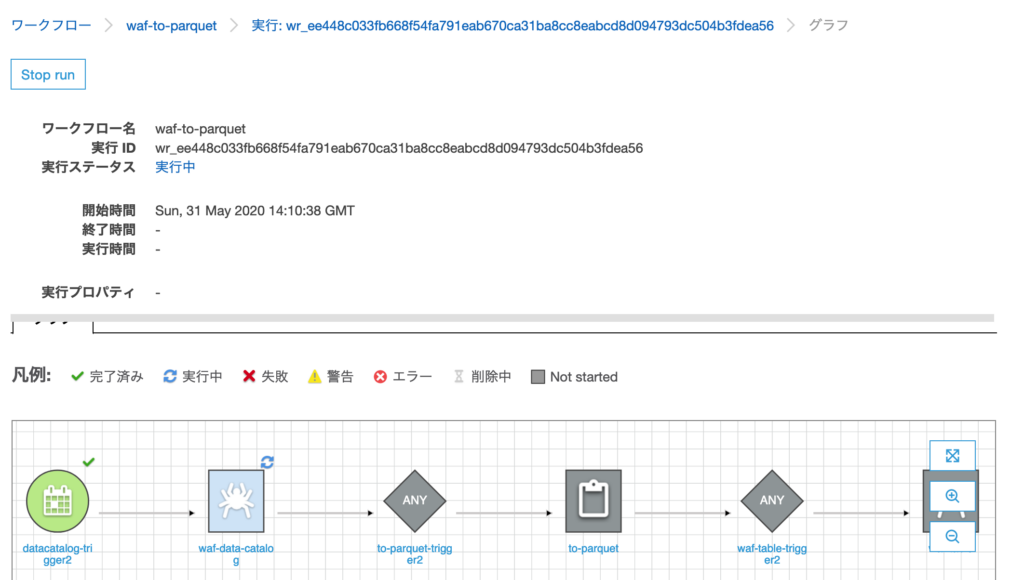
全て完了するとこうなる。

補足 : Glue Trigger
ワークフロー内で作成したトリガーは、左サイドメニューのトリガーコンソールから確認できる。

ただし、トリガーはジョブ・クローラに紐付いていないため、編集しようとするとエラーが出て編集できない。。
遭遇したエラー
AnalysisException: ‘\nDatasource does not support writing empty or nested empty schemas.\nPlease make sure the data schema has at least one or more column(s).\n ;’
Glue Job で読み込み先のパーティションが存在しない場合に発生する。
- ☓ : year=2020/month=5/day=31/hour=5
- ○ : year=2020/month=05/day=31/hour=05
An error occurred while calling o67.getCatalogSource. Table columns not found.
Jobスクリプト内で datasource0 の table_name の指定が間違っていた。
参考
AWS Glue のパーティション分割されたデータを使用した作業
AWS GlueでApache Sparkジョブをスケーリングし、データをパーティション分割するためのベストプラクティス

コメント