
- 概要
- AWS コンソールから操作
- 遭遇したエラー
- An error occurred while calling o113.resolveChoice. No such file or directory
- An error occurred while calling o129.pyWriteDynamicFrame. Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied;
- An error occurred while calling o129.pyWriteDynamicFrame. java.lang.NullPointerException
- AnalysisException: ‘Parquet data source does not support array<null> data type.;’
- 参考
概要
やりたいこと
すでに Json として出力された WAF ログを Parquet 形式に変更する。
Athena で検索できるところまでやる。
AWS WAF ログを Json 形式で S3 にエクスポートするところまでは以下で行った。
以下のように、カラム名なしのパーティションで JSON 形式で保存されているログを、カラム名なしのパーティションで Partition 形式で保存し直す。
- 変更前 : S3://waf-logs-no-parquet/COLUMNS/year=2020/month=05/day=29/hour=05/waflog.json
- 変更後 : S3://waf-logs-no-parquet/COLUMNS-parquet/year=2020/month=05/day=29/hour=05/waflog.parquet
流れは以下。
- Crawler でS3上のファイルを読み込み、データカタログを作成
- Job で Parquet 形式に変更する
- Crawler で変換後のデータを読み込み、データカタログを作成し
- 変換後のデータカタログを Athena で検索
AWS Glue
AWS 公式から Glue のチュートリアルが提供されている。
Classmethod の記事も参照しながら進めると AWS Glue を理解できる。
Glue Crawler
S3 上にあるログファイルからスキーマを読み出し、 Glue データカタログを作成する。
AWS Glue Crawler は AWS リソース上のデータソースをスキャンし、スキーマ情報を抽出しメタデータを生成、自動的にデータカタログを作成する機能を持つ。
Glue Job
JSON 形式のログを Parquet 形式に変換したログを新規に保存する。
他にもスキーマ情報を削除したりする等の ETL 機能もあるが、今回は使わない。
AWS コンソールから操作
前提として、S3 に AWS WAF ログが出力されているものとする。
Glue 用 IAM Role 作成
AWS Glue 実践入門 環境準備編(1):IAM権限周りの設定について という記事を参考に、以下の IAM Role を作成。
「AWSGlueServiceRole-」というプレフィックスは必須。
- AWSGlueServiceRole-waf-log
Policy は以下をアタッチ。S3 へのアクセス権は絞ったほうがいいが検証用なので。
- AWSGlueServiceRole
- AmazonS3FullAccess
Glue Crawler でデータカタログ作成
Glue Job で必要になるデータソースを Glue Crawler を利用して作成する。
- クローラの名前 : waf-data-catalog
- crawler source type : Data stores
- データストアの追加
- データストアの選択 : S3
- インクルードパス : s3://waf-logs-no-parquet/COLUMNS/
- 別のデータストアの追加 : いいえ
- IAM ロールの選択
- 既存の IAM ロールを選択
- IAM ロール : AWSGlueServiceRole-waf-log
- クローラのスケジュール
- 頻度 : 毎時
- Start Minute : 05
- クローラの出力を設定する
- データベース : glue-datacatalog
作成したクローラを選択し、「クローラの実行」より一度実行し、 columns というテーブル(データカタログ)が作成される。
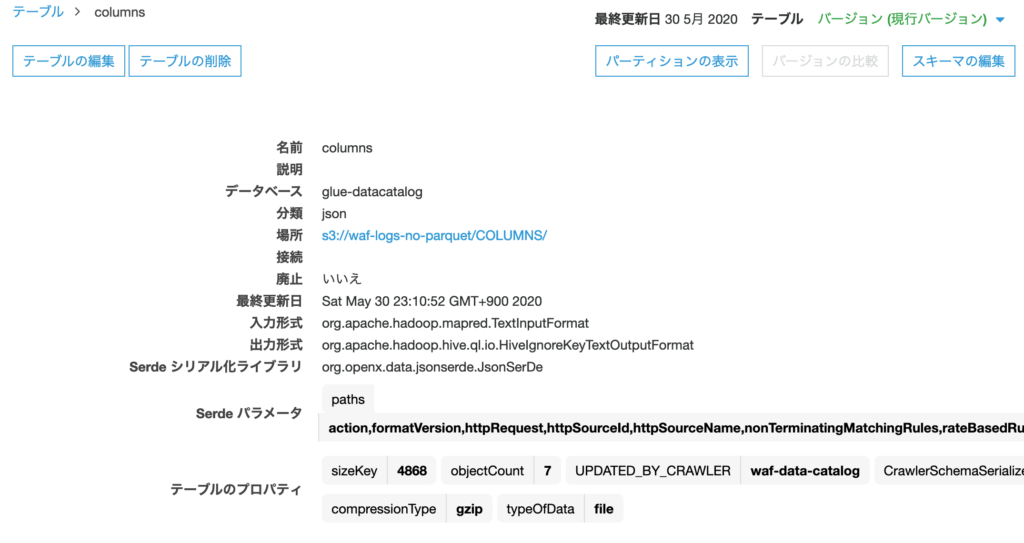
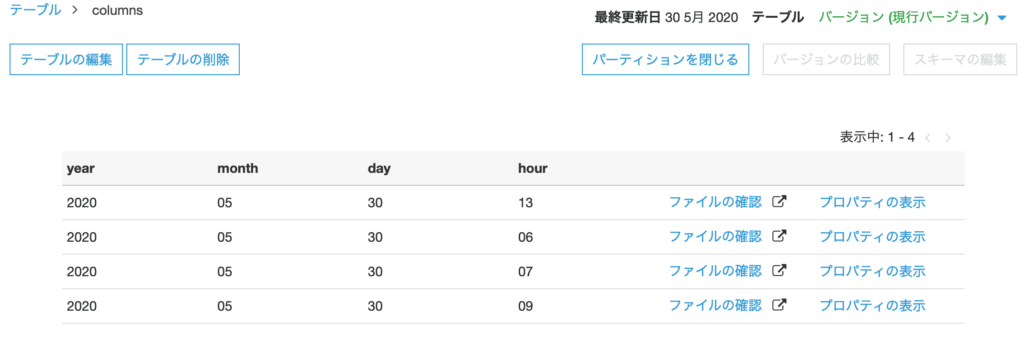
パーティションとして year, month, day, hour が存在することを確認。
Glue Job で Parquet 形式のログを作成
Glue Job で Parquet 形式のログを作成する。ここはノンコーディングで作成できる。
- ジョブプロパティの設定
- 名前 : to-parquet
- IAM ロール : AWSGlueServiceRole-waf-log
- Type : Spark
- Glue version : Spark 2.4, Python 3 (Glue version 1.0)
- このジョブ実行 : AWS Glue が生成する提案されたスクリプト
- スクリプトファイル名 : to-parquet
- スクリプトが保存されている S3 パス : デフォルト
- 一時ディレクトリ : デフォルト
- データソースの選択 : columns
- 変換タイプを選択します。 : スキーマを変更する
- データターゲットの選択
- データターゲットでテーブルを作成する
- データストア : Amazon S3
- 形式 : Parquet
- ターゲットパス : 変換後のログを出力したいところ
- ソース列をターゲット列にマッピングします。 : デフォルト
自動で以下のようなコードが出力される。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "waf", table_name = "columns", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "waf", table_name = "columns", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("timestamp", "long", "timestamp", "long"), ("formatversion", "int", "formatversion", "int"), ("webaclid", "string", "webaclid", "string"), ("terminatingruleid", "string", "terminatingruleid", "string"), ("terminatingruletype", "string", "terminatingruletype", "string"), ("action", "string", "action", "string"), ("terminatingrulematchdetails", "array", "terminatingrulematchdetails", "array"), ("httpsourcename", "string", "httpsourcename", "string"), ("httpsourceid", "string", "httpsourceid", "string"), ("rulegrouplist", "array", "rulegrouplist", "array"), ("ratebasedrulelist", "array", "ratebasedrulelist", "array"), ("nonterminatingmatchingrules", "array", "nonterminatingmatchingrules", "array"), ("httprequest", "struct", "httprequest", "struct"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("timestamp", "long", "timestamp", "long"), ("formatversion", "int", "formatversion", "int"), ("webaclid", "string", "webaclid", "string"), ("terminatingruleid", "string", "terminatingruleid", "string"), ("terminatingruletype", "string", "terminatingruletype", "string"), ("action", "string", "action", "string"), ("terminatingrulematchdetails", "array", "terminatingrulematchdetails", "array"), ("httpsourcename", "string", "httpsourcename", "string"), ("httpsourceid", "string", "httpsourceid", "string"), ("rulegrouplist", "array", "rulegrouplist", "array"), ("ratebasedrulelist", "array", "ratebasedrulelist", "array"), ("nonterminatingmatchingrules", "array", "nonterminatingmatchingrules", "array"), ("httprequest", "struct", "httprequest", "struct"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://waf-logs-no-parquet/COLUMNS-partition"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://waf-logs-no-parquet/COLUMNS-partitions", format = "parquet", transformation_ctx = "datasink4")
job.commit()
「ジョブの実行」を行うと指定した S3 バケットに Parquet 形式のログが保存される。
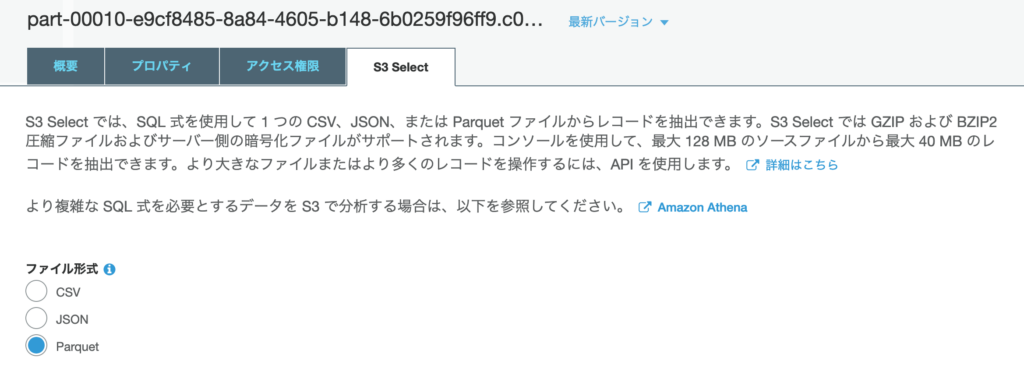
S3 Select で Parquet 形式を指定してプレビューでログ内容を確認できること。
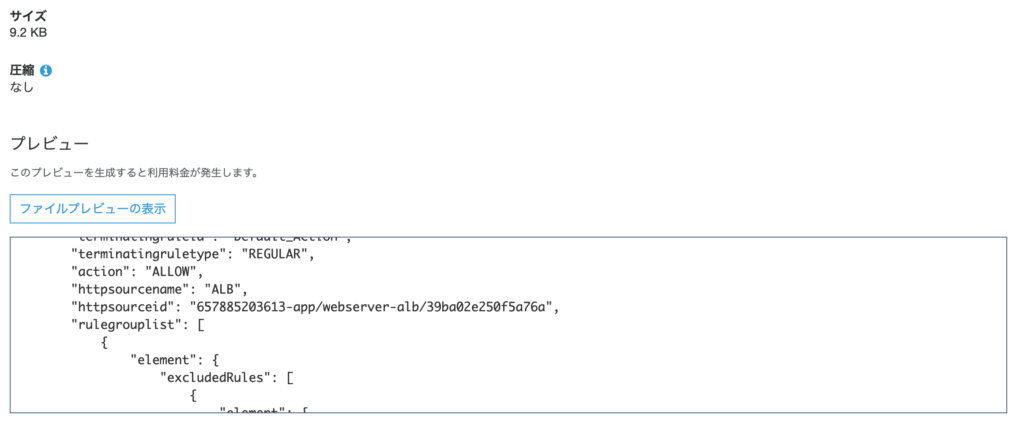
パーティション化された Parquet ログを作成
Glue のデフォルトのコードだとパーティション化がされていないログが出力されてしまう。
下記を参考に、Glue が作成したコードを修正する。
datasink4 に代入する式の connection_options の json 内に partitionsKeys を追加する。
datasink4 = glueContext.write_dynamic_frame.from_options(
frame = dropnullfields3,
connection_type = "s3",
connection_options = {"path": "s3://waf-logs-no-parquet/COLUMNS-partitions/", "partitionKeys": ["year", "month", "day", "hour"]},
format = "parquet",
transformation_ctx = "datasink4")
コードを保存し、再度 Job を実行すると、 指定した S3 バケット内にカラム名有りのパーティションが作成され、Parquet 形式のファイルが出力された。
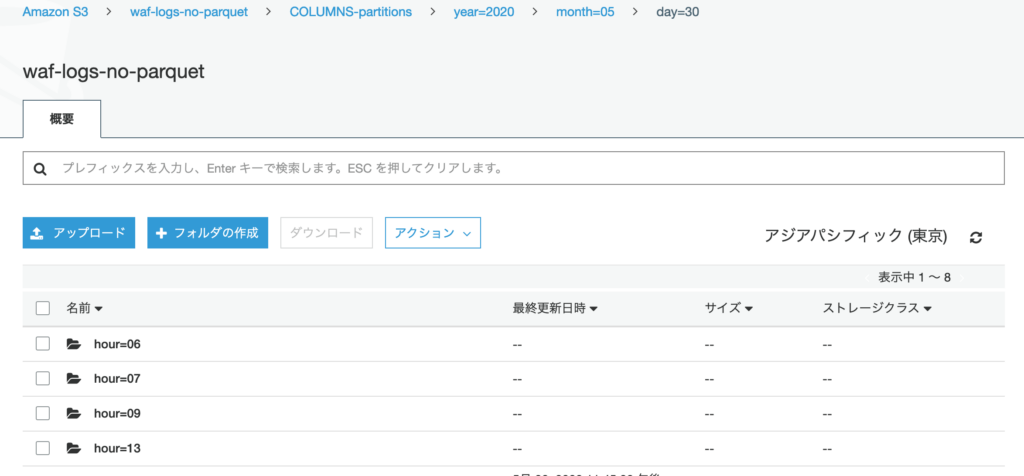
出力されたログに対して、改めてテーブルを作成する。
Athena で検索するためのテーブルを作りたいため、別のデータベースを選択しておく。
- クローラの名前 : waf-table
- crawler source type : Data stores
- データストアの追加
- データストアの選択 : S3
- インクルードパス : s3://waf-logs-no-parquet/COLUMNS-partitions/
- 別のデータストアの追加 : いいえ
- IAM ロールの選択
- 既存の IAM ロールを選択
- IAM ロール : AWSGlueServiceRole-waf-log
- クローラのスケジュール
- 頻度 : 毎時
- Start Minute : 10
- クローラの出力を設定する
- データベース : waf
実行すると columns_partitions というテーブルが作成される。
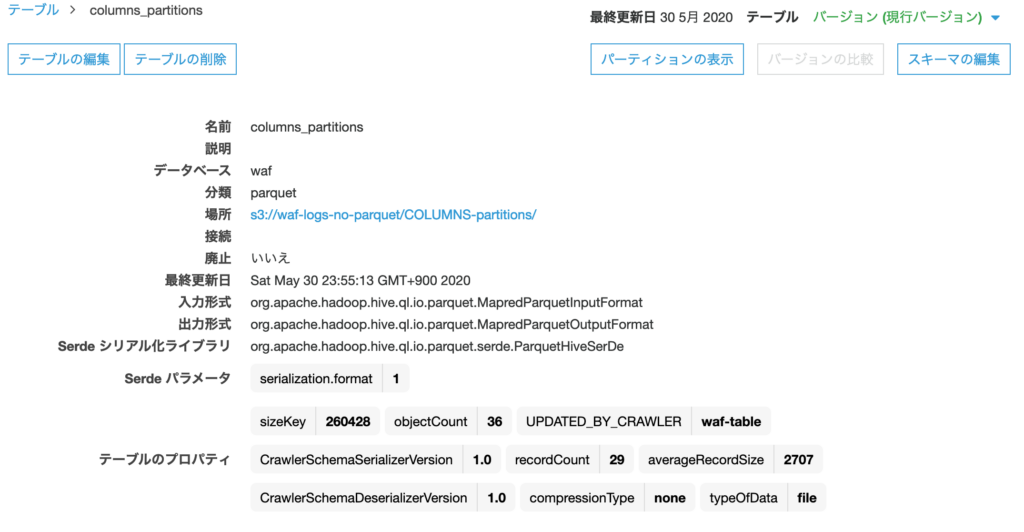
パーティションが区切られている。
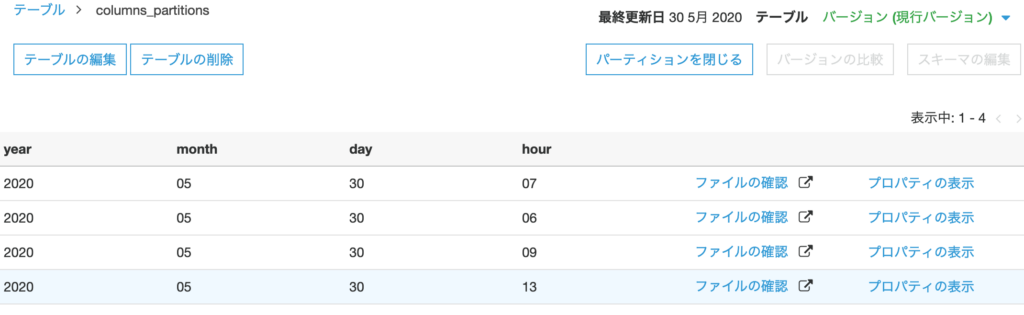
Athena でもパーティションを確認できた。
show partitions columns_partitions;
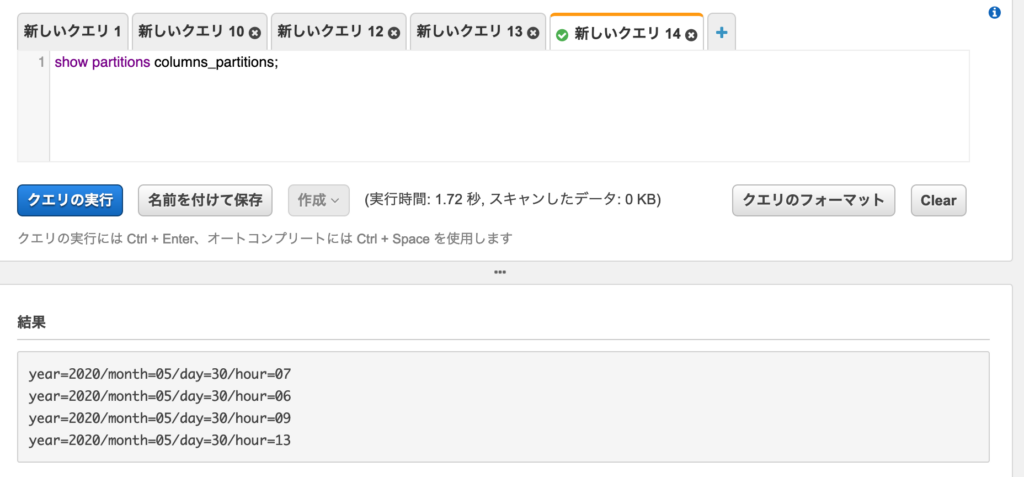
次回は Glue job の自動化を行う。
遭遇したエラー
An error occurred while calling o113.resolveChoice. No such file or directory
クローラーの IAM Role とジョブの IAM Role が異なっているとき。
An error occurred while calling o129.pyWriteDynamicFrame. Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied;
バケットへのアクセス権がない。
An error occurred while calling o129.pyWriteDynamicFrame. java.lang.NullPointerException
IAM に AmazonS3FullAccess を追加で解決。
AnalysisException: ‘Parquet data source does not support array<null> data type.;’
Glueの使い方的な②(csvデータをパーティション分割したparquetに変換) を参考にパーティションを作ろうとしたときに出たエラー。

コメント